Вступление
У меня чувство досады от того что данные представлены в сети не в виде "данных". Что такое "данные"? Это то что может понять компьютер. ... Я хочу представить себе мир, в котором все разместили свои данные в сети.
Тим Бернерс Ли (Руководитель W3C, 2009, конференция TED).
Семантическая вёрстка — это когда я верстаю таблицами и думаю о таблицах. Или что-то типа того.
Алексей Шилов aka mr.troll.
Четыре года назад мы даже не думали о HTML5 (а многие ждали XTML 2.0).
Три года назад нам сказали, что HTML5 непременно к 2020 году будут использовать.
Два года назад мы узнали, что HTML5 уже можно использовать.
Год назад оказалось, что HTML5 давно все используют.
Сегодня, всё что не имеет доктайпа <!doctype html> выглядит остатками мамонтов (и пахнет точно так же).
Html5 принёс нам много-много всяких спецификаций и технологий. И хотя главное назначение html5 — это расширение мультимедийных возможностей браузера (в черновиках html5 назывался как Web Applications), всякие video и audio теги, их кодеки, canvas и WebGL, инкапсуляция (sandboxing) ифреймов и объектов, и т.п. — всё это довольно скучные для обсуждения вещи. То, что действительно интересно обсуждать — это новые семантические теги — nav, article, section, header, footer, и дюжину других.
О семантических тегах
Неделю назад (точнее уже три недели назад) вышла статья "Let’s Talk about Semantics (by HTML5 Doctor)", я настоятельно рекомендую с ней ознакомиться прежде чем читать далее.
Откуда же взялись эти семантические теги? Компании Google и Опера выборочно изучили примерно 4 миллиона популярных страниц в интернете, отчёт о результатах доступен например здесь: http://dev.opera.com/articles/view/mama-markup-report-part-2/.
Вот топ 10 самых популярных значений атрибутов Name и Id :
| Name attribute value |
frequency |
|
Id attribute value |
frequency |
| keywords |
2,189,708 |
footer |
288,061 |
| description |
2,100,858 |
content |
228,661 |
| generator |
943,496 |
header |
223,726 |
| robots |
937,844 |
logo |
121,351 |
| author |
818,017 |
container |
119,877 |
| movie |
530,989 |
main |
106,327 |
| quality |
504,666 |
table1 |
101,677 |
| revisit-after |
475,765 |
menu |
96,161 |
| copyright |
423,210 |
layer1 |
93,920 |
| progid |
281,339 |
В своей статье, HTML5Doctor, нас убеждают в том, что основываясь именно на данных списках и были приняты решения о внесении новых тегов в спецификацию HTML5. Однако, из таблицы видно что это не совсем так. Я очень люблю id="footer" или id="content" — но я никогда не использовала id="article". Значение "article" — находиться на 186 месте в рейтинге значений класса и на 728 месте в рейтинге значений id. Т.е. данные атрибуты используют меньше чем 0.1% вебмастеров из статистики. Я считаю что это очень показательные цифры, я не могу понять почему html5doctor ссылается на них.
Так откуда же появились новые теги? Если ответить коротко — они просто придуманы редактором спецификации html5 Яном Хиксоном (Ian Hickson). Когда я спросила его об этом два года назад, он ответил примерно следующее:
Element names in HTML have little relationship to the usage of those names
in reality, to be honest. I wouldn't pay too close attention to the
meaning of the element names in common conversation; only their definition
in the spec matters.
- Ian Hickson (16 Mar 2010)
Это честно. И вполне разумно. Я верю что Ян Хиксон проделал колоссальную работу по составлению списка данных тегов и максимально конкретных описаний и примеров к ним. Однако большой проблемой является то, что все веб-разработчики по разному понимают данную спецификацию (ситуация чем-то похожа на библию). Кто-то прочитал и понял неправильно, кто-то подумал что он понял правильно, у многих вообще не было времени чтобы прочитать её, но было время прочитать статьи популярных авторов которые писали о том как поняли они, и т.п.
Также есть множество веб-разработчиков, которые считают, что в вёрстке названия как-то связаны с той ролью, которую выполняет тег. Я сама вкладываю в термин "семантика" именно такое значение. Было бы логично предполагать, что если тег a — означает anchor, h1 — заголовок первого уровня, abbr — аббревиатуру, то и тег menu — можно было бы использовать для меню, nav — для любого обособленного блока со ссылками на другие страницы и навигации по сайту, header — как шапку страницы, article хмм... как статью, а section — какую-то часть содержания, например той же статьи. Однако же можно привести примеры вёрстки, где, по спецификации, данные теги будут обозначать совершенно другое, и наоборот, можно привести примеры, где все значения соответствуют совершенно другим тегам.
Например тот же Ян Хиксон не рекомендует использовать тег <menu type="list"> для разметки меню. Вместо этого советуется <nav><ul></ul></nav> и т.п. Так же по спецификации возможно не рекомендуется использовать <nav> для разметки такой навигации как "хлебные крошки" и формы поиска, хотя для меня это было бы семантично (о чём я не раз писала три года назад тут и тут).
Что же я думаю по поводу новых семантических тегов? У них есть ряд положительных свойств:
- В будущем можно действительно улучшить обработку и индексацию данных тегов поисковыми роботами и другими программами.
- Ну, по крайней мере это лучше чем div.
Но есть и ряд и недостатков:
- Названия элементов — не связаны с их значением. Например article — это любой объект который сам по себе представляет какой-то контент, а section — это группирующий элемент, например когда нужно связать много <article> воедино. (Тут важно группировать по смыслу, а не как визуальную обёртку ). Вместо <article> безусловно лучше был бы <zoidberg>.

- Никто честно не говорит вслух — почему верстальщик должен использовать семантические элементы вместо div? Единственный ответ — "для поисковых роботов". Самому верстальщику — долгие раздумья, над тем какой тег использовать, приносят больше вреда чем пользы, imho. (За исключением конечно того, что таблицы надо верстать таблицами, а списки — списками. Прочие тривиальные вещи объяснял, например, Вадим Макеев, однако его объяснение про html5 не очень внятное). Веб-браузерам довольно всё равно какую кашу из тегов написал верстальщик. Прочие браузеры, типа машин Брайля — в России например составляют 0% от общего числа. Поэтому вёрстка html5 тегов — важна для роботов, и только.
- Описания довольно размыты и их толкование во многом субъективно. В html 4.01 было меньше разночтений.
- Очень мало примеров. В идеале — нужно создать сайт, html5samples — где собрать типовые примеры вёрстки различных сайтов. Блога, Каталога, Магазина и т.п. С подсветкой при наведении того, какие теги использовались и описанием почему. Если бы были конкретные примеры — тогда бы и html5doctor.com был бы не нужен. Вот Bruce Lawson например сделал html5 тему для wordpress, уже хоть что-то.
В html есть клёвые "стерильные" элементы div и span названия которых ничего не значат. (С большой натяжкой div можно расшифровать как division). Я считаю эти имена лучше подходят для html тегов чем "семантические" названия.
WAI-ARIA и Микроформаты
Это совершенно другой путь развития смысловой аннотации содержания. Несмотря на то что он менее удобный — верстальщику приходиться полагаться на атрибуты, а не на сами по себе теги — данный метод позволяет точно добавить семантику. Например у вас был код типа
<div style="font-size:30px;">some big big caption</div>
Несмотря ни на что — это полноценная html разметка. А затем вуаля
<div style="font-size:30px;" role="heading" aria-level="2">some big big caption</div>
Разметка показывает, что теперь это осмысленный заголовок второго уровня (конечно для тех же целей есть <h2>).
Либо у вас был такой код:
<h3>Елена Лунная</h3>
<address>askme@usabili.ru</address>
Который легко можно превратить в визитную карточку
<div class="vcard">
<h3 class="fn n">
<span class="given-name">Елена</span>
<span class="family-name">Лунная</span>
</h3>
<address class="email">askme@usabili.ru</address>
</div>
У микроформатов преимуществ гораздо больше:
- Нет никакой иллюзии в том что они используются в основном для поисковиков и других ботов.
- Описания микроформатов всегда конкретны. Т.е. на каждый случай — свой микроформат.
- Они отлично документированы.
- В составлении микроформатов (например от Schema.org) активно участвуют сами поисковые системы — как следствие они уже хорошо поддерживаются ими.
- Их проще понять
Из недостатков:
- Их сложнее запомнить (если под рукой нет ссылки на wiki)
- Они занимают больше места чем теги. (Однако когда не было CSS, всевозможное оформление занимало ещё больше места в html коде).
Эксперимент
Итак... После статьи на html5doctor я решила поставить небольшой эксперимент, касающийся в основном html5 тегов. Я сделала вот такой макет страницы каталога онлайн магазина:
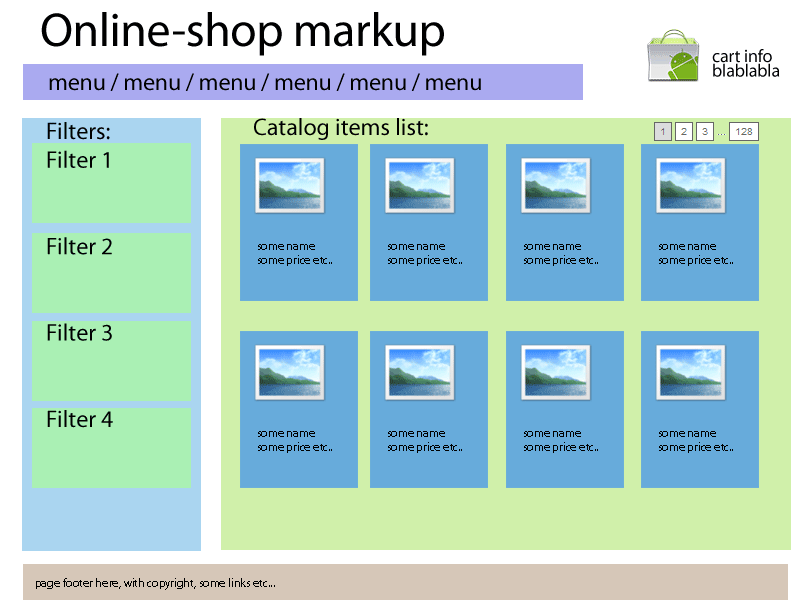
и спросила некоторых известных людей как бы они её сверстали, по пунктам. Текст письма был примерно такой:
I have a question about semantic markup online store pages .
I'm wondering which tags you would use for the following items (see
attachment picture):
1) a horizontal menu of links to different pages
2) the entire block containing the page header (logo, cart block, and a
horizontal menu).
3) the block containing the search filters (the most important
navigation in curtain shop)
4) one filters block
5) block containing shop items
6) block of one items (which includes photo, item title, etc.)
7) pagination
8) page footer.
Can I quote your answer in my blog?
Thank you.
Данный вопрос я послала разным веб-евангелистам. Многие конечно не ответили (например html5doctor, работа у них такая, не отвечать на вопросы) — это нормально. Однако не ответил кое-кто кто обещал — это досадно. Впрочем я не буду называть тех кто не ответил, лучше поприветствуем тех кто смог ответить. Итак:




{kind=link}
{kind=link}
{kind=link}
{kind=link}